V sobotu ráno 3. února 2018 se sešlo 16 začínajících programátorek a programátorů v Národní technické knihovně v Dejvicích, aby si vyzkoušeli datovou analýzu. Samostatné práci v rámci začátečnického hackathonu předcházelo setkání s členy týmu Seznam.cz, kteří se věnují analýze dat. Ti nejprve představili svoji práci a potom účastníkům ukázali data, která Seznam poskytl k učení, procvičování a analýze pomocí Pythonu. Jednalo se o dva datasety z databáze Srealit, kluci představili strukturu dat i možné formy interpretace a na co si dát pozor, poté poskytli data ke stažení všem a ti si je začali sami osahávat.
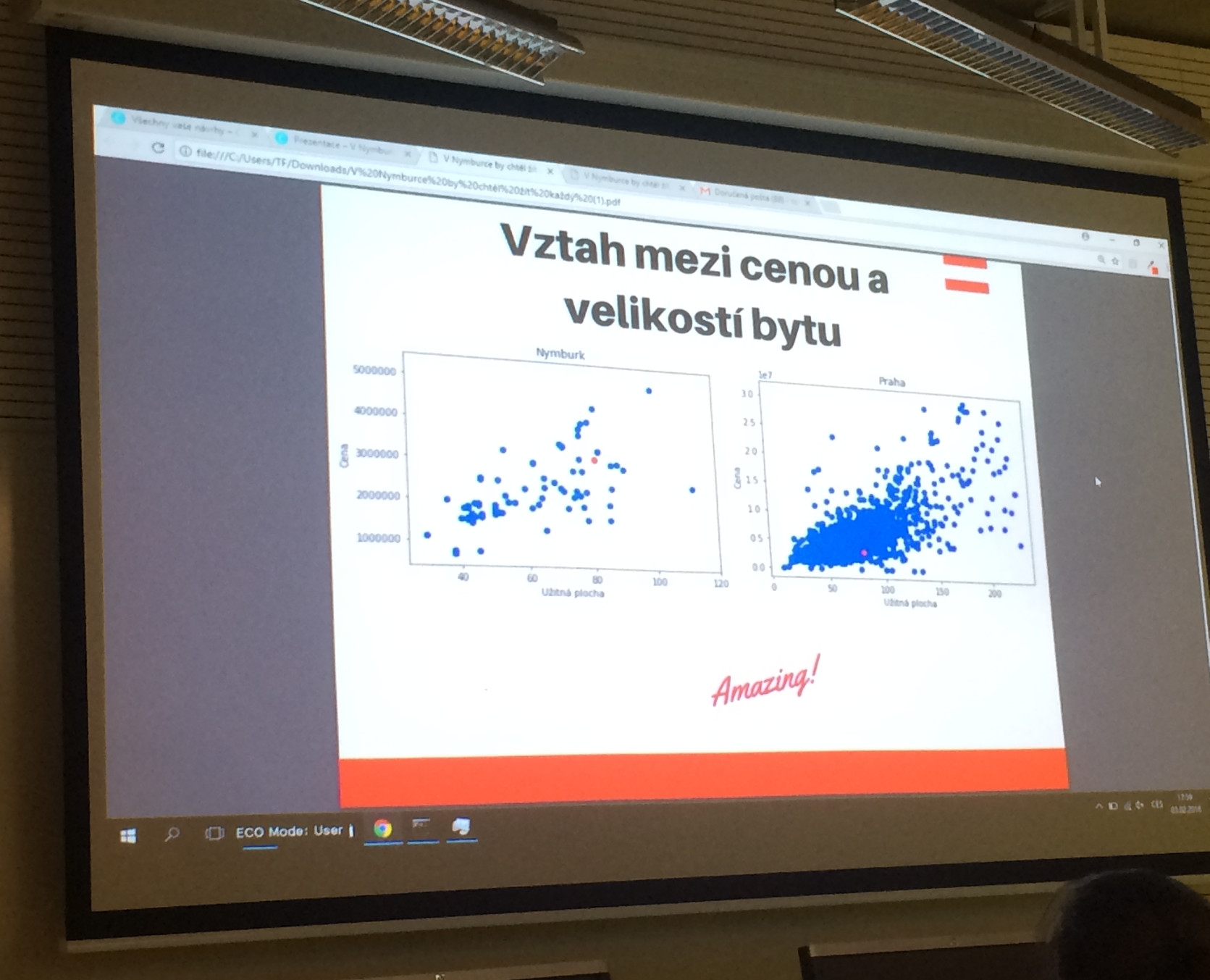
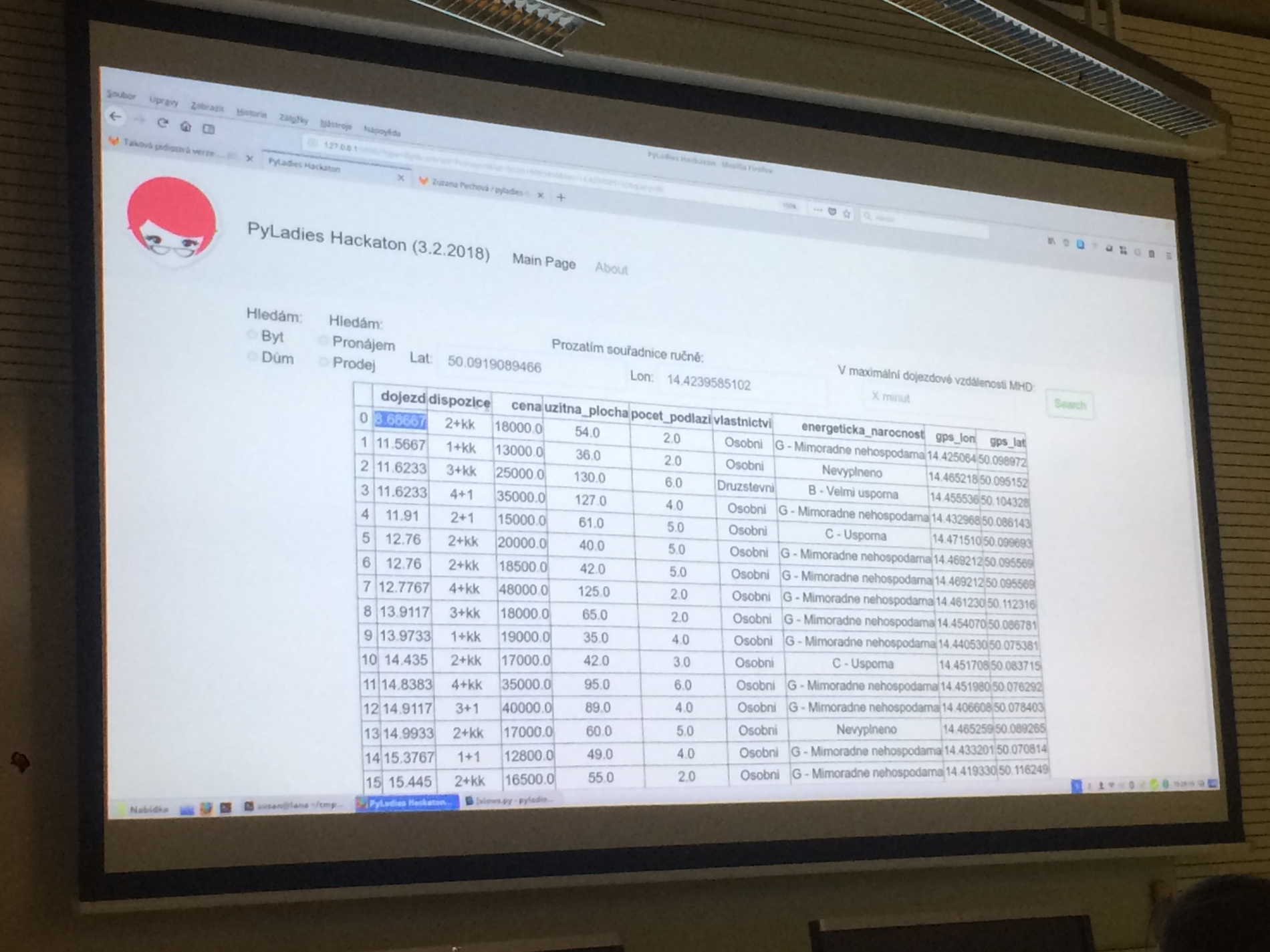
Po prvních dvou rozehřívacích úkolech pro všechny k seznámení s datasety se začali účastníci dělit do skupinek, které pak již budou pokračovat v práci na svých projektech samostatně. Rozhodující je vybrat dobré téma! Sreality nabízí aktuálně velmi palčivou problematiku bydlení, aneb jak neskončit pod mostem, když mosty v Praze teď nejsou v nejlepším stavu. První odvážná analytička se přihlásila: „Já jsem shodou okolností přidala inzerát na Sreality a je tam, ráda bych si to proto srovnala.“ Hned vzápětí se zvedla další ruka: „Kupujeme byt, taky by se mi to hodilo! Jsem s tebou.“ Týmy a témata se začaly rychle skládat dohromady. Další skupina se zaměřila na vliv rekonstrukce na cenu nemovitostí: „Můžeš mě přidat k té rekonstrukci?“, „Já bych taky rekonstruoval.“ Další týmy se vrhly na měření vlivu vzdálenosti bytu od centra města a zastávek MHD, v závislosti na jeho ceně – kam až kupec zajde?
První vlnu brainstormingu a konzultování přípravy přerušil společný oběd a po něm následovaly další hodiny práce. Za oknem krátce sněžilo a potemnělo, ale duhová podlaha NTK nás nenechala usnout. Po pečlivé analýze a dlouhém systematickém rozebírání alternativ došlo večer na prezentace výsledků. Všechny skupiny dokončily své projekty a k analýze přistoupily s odvahou a kreativitou. Porota složená z organizátorů a koučů ohodnotila přístup k řešení projektu, práci v týmu, správnost postupu, ale i užitečnost. V součtu těchto kritérií zvítězila analýza vlivu rekonstrukce na výslednou cenu bytu, a tedy odpověď na otázku – prodávat před, či po rekonstrukci? Další prezentovaný projekt byla analýza konkurenceschopnosti konkrétního inzerátu bytu oproti ostatním. Velmi užitečnou by mohla být i jednoduchá aplikace, jež vyhodnotila polohu eventuálních nemovitostí z nabídky vzhledem k nejbližší stanici MHD. Během konečných prezentací měli účastníci možnost i kriticky ohodnotit cizí řešení a zamyslet se nad tím, kde a proč vznikly jaké odchylky.
A co na to kouč Petr?#
Workshop byl svým formátem vlastně hackathon, ale hlavním cílem bylo něco se naučit, setkat se s novými lidmi, trochu networking… spíš než vytvořit funkční projekt (i k tomu se ale jeden tým přiblížil). Učení probíhalo jak formou přednášky na začátku, tak i mezi účastníky navzájem, radami od pomáhajících koučů a samozřejmě i googlením :) Nikdo se nenudil s tím, že by už všechno znal.
Všechny týmy si pro práci zvolily knihovnu Pandas. Ta na jednu stranu práci s daty usnadňuje, ale pokud s ní člověk nemá zkušenosti, tak neustále hledá, jak nějakou konkrétní věc udělat. Třeba i něco, co by nakonec bylo jednodušší v „čistém“ Pythonu. Pro začátečníky může být jednodušší pracovat s hodnotami tabulky (DataFrame) jednotlivě, což u Pandas bohužel není vhodné, protože je to docela pomalé; ale aspoň byl při běžícím výpočtu čas zajít si na kafe :)
Většina týmů použila prostředí Jupyter Notebook. Všichni účastníci přišli na workshop s již připraveným softwarem na svých noteboocích, což ušetří hodně času. Praktickým problémem bylo předávání dat mezi členy týmů, jeden z týmů to vyřešil pomocí GitHubu.
Co se týká samotné práce s daty, tak bych řekl, že účastníkům chyběly určité zkušenosti a návyky z oblasti statistiky. Často byl výstupem týmu sloupcový graf s průměrnou hodnotou, která ale nenese moc informace – nebylo zřejmé rozdělení dat, možné ovlivnění outliery… Nezbyl moc prostor hledat v datech nějaké další závislosti a souvislosti. Ale zase nejdříve je potřeba zvládnout nástroje, jako jsou Pandas, a toto workshop právě splnil.
Týmy si procvičily i čištění dat. Ukázalo se, že i tak jasná položka, jako je „cena,“ nemusí být úplně směrodatná, pokud je v textu inzerátu upřesněno, že je to cena např. pouze za částečný podíl vlastnictví činžovního domu. Nejvíce se do dat zanořil vítězný tým, který zkoušel různé možnosti, jak z textu inzerátu zjistit údaje o rekonstrukci dané nemovitosti, což bylo uvedeno někdy i dost nepřímo.
Děkujeme všem skvělým účastníkům, neúnavným PyLadies koučům, NTK a samozřejmě Seznamu.
Petra Vondrová, Pavlína Froňková a Petr Messner
Své postřehy sepsala i jedna z účastnic, Michaela Šebestová: Můj první datový hackathon